
阿修罗
October 1, 2020 | 1600 Words | Read in about 8 Min | 本文总阅读量次
从HelloWold开始,深入浅出C++ 20 Coroutine TS
缘起
前一阵子在查看asio库的时候看到在example目录中已经提供了coroutines_ts代码。很是好奇,便慢慢翻看代码,在感叹Coroutine给异步编程带来的优雅简洁的同时也带来了许多概念上的复杂和难以理解。由于C++ Coroutine还是一个比较新的概念,各个编译器厂商的实现还处于实验性的阶段[1] ,网上的资料少而松散。由此内心涌出一个念头想把自己的学习过程记录下来以期帮助后面学习的人。
从HelloWorld说起
再过两年这个世界的第一条HelloWorld代码就要有50年历史了[2] ,在此先提前蹭下热点,:)…
#include <iostream>
int main() {
std::cout << "hello, world" << std::endl;
return 0;
}
这是一段平淡无奇的符合C++98标准的代码,你甚至可以用古董级编译器GCC 4.3都能编译通过[3]。但是我希望通过对这段代码的演化带领大家学习了解C++ 20中的Coroutine。
这段代码的作用很简单,打印一条"hello, world",执行的也很快。但是这个世界并不总是那么简单美好,如果打印的逻辑非常耗时(特别是读取磁盘文件和进行网络请求时)而又需要频繁的调用就有些尴尬了,好了,我们改下代码来模拟这种情形:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std::chrono_literals;
void remote_query() {
// 假设这是个远程网络请求
std::this_thread::sleep_for(4s);
std::cout << "hello, world" << std::endl;
}
int main() {
for (;;) {
remote_query();
}
return 0;
}
改过后的代码不停的进行耗时的远程调用,每次远程调用需要消耗4秒的时间才能返回。可以看到,每次进行调用时程序都要暂停住(也就是卡住)而做不了其它事情。如果这是个带UI(用户界面)的程序,每次进行调用界面就要卡住,用户肯定是不能忍受的。
注意
上面的代码由于使用了thread[4](C++ 11)和chrono_literals[5](C++ 14),所以编译器需要支持C++ 14标准。
多线程+Callback解决方案
为了解决上面的问题,我们对上面的代码进行如下改造:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std::chrono_literals;
#include <string>
#include <future>
void remote_query(uint32_t query_index, std::function<void(uint32_t)>&& callback) {
std::thread t(
[query_index, callback = std::move(callback)]() {
std::this_thread::sleep_for(4s);
std::cout << std::to_string(query_index) + " times query: Hello, world!" << std::endl;
callback(query_index);
});
t.detach();
}
void remote_callback(uint32_t query_index) {
remote_query(++query_index, remote_callback);
}
int main() {
remote_query(1, remote_callback);
while (true)
{
std::this_thread::sleep_for(1s);
std::cout << "main thread doing other things..." << std::endl;
}
return 0;
}
打印结果:
main thread doing other things...
main thread doing other things...
main thread doing other things...
main thread doing other things...
1 times query: Hello, world!
main thread doing other things...
main thread doing other things...
main thread doing other things...
main thread doing other things...
2 times query: Hello, world!
main thread doing other things...
main thread doing other things...
是的,我们可以通过多线程解决卡顿的问题,但这是个好的方案吗?不说线程的开销(其实创建和销毁一个线程无论从时间还是空间上来说都是非常大的开销),单从代码的组织来看也足够让人头疼的了。上面的代码只是循环调用同样的远程方法,如果remote_callback调用remote_query1(另一个远程调用),remote_query1回调中再调用remote_query2…如此下去代码逻辑将会非常恐怖。如果不能明白我说的是什么意思,callback hell 了解下:), 为什么说是恐怖,因为这完全不符合人类的思维逻辑。人类喜欢的代码是有条不紊的按步执行,而不是在各个回调中跳来跳去。最好就像前面的同步代码,一个请求走完再执行下一个请求。
主角登场
有没有什么方法解决这种复杂性呢?有的,技术牛人们早已发现这个问题并且给出了设计模型,有类似于libevent的Reactor模式[6],也有asio的Proactor模式[7]。但Reactor,Proactor模式的核心思想都是通过事先注册回调函数,收到消息再根据消息内容查找并执行回调,有效的将层层包裹的回调给摊平以达到降低回调函数管理的复杂度。但是无论Reactor还是Proactor调用逻辑和回调逻辑还是被硬生生的给割裂开了。如何弥合这里的割裂呢?这就需要请出我们今天的主角Corouter了,还是先看代码吧:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std::chrono_literals;
#include <string>
#include <future>
std::future<std::string> remote_query(uint32_t query_index) {
return std::async([query_index]() {
std::this_thread::sleep_for(4s);
return std::to_string(query_index) + " times query: Hello, world!";
});
}
std::future<void> remote_query_all() {
uint32_t query_index = 0;
for (;;)
{
std::string ret = co_await remote_query(++query_index);
std::cout << ret << std::endl;
}
}
int main() {
remote_query_all();
while (true)
{
std::this_thread::sleep_for(1s);
std::cout << "main thread doing other things..." << std::endl;
}
return 0;
}
打印结果:
main thread doing other things...
main thread doing other things...
main thread doing other things...
1 times query: Hello, world!
main thread doing other things...
main thread doing other things...
main thread doing other things...
main thread doing other things...
2 times query: Hello, world!
main thread doing other things...
main thread doing other things...
main thread doing other things...
看到了吗?打印结果还是一样的,但是回调没有了, 从代码上看函数remote_query_all的逻辑也是在一个for循环中按步执行。好了,讲到这里只是希望你能直观的体会到使用Coroutine的作用和好处,但是你心中一定会有n个问号。
- 这不科学呀,
remote_query返回值不是std::future<std::string>吗? 怎么直接赋值给std::string了? co_await又是什么鬼?remote_query是个异步调用, 返回的ret直接用会不会崩溃?- …
请少安毋躁, 暂时按下心中的疑惑,因为这边的水很深,坑很大,不是三言两语能够解释的清楚的。我会尽量努力在后面的内容中消除你心中的困惑。
先从定义说起
翻开cppreference看看协程的定义[8]:
协程是能暂停执行以在之后恢复的函数。协程是无栈的:它们通过返回到调用方暂停执行,并且从栈分离存储恢复所要求的数据。这允许编写异步执行的顺序代码(例如不使用显式的回调来处理非阻塞 I/O),还支持对惰性计算的无限序列上的算法及其他用途。
若函数的定义做下列任何内容之一,则它是协程:
. 用 co_await 运算符暂停执行,直至恢复
. 用关键词 co_yield 暂停执行并返回一个值
. 用关键词 co_return 完成执行并返回一个值
读完之后似乎还是什么都不知道,好吧,现在我们试着逐句翻译成“白话文”。
-
协程是能暂停执行以在之后恢复的函数。
这里的协程就是前面说的
Coroutine, 这句说出了协程的本质。首先它是一个函数,然后这个函数与普通函数的区别是能够“暂停”和“恢复”执行代码。所以协程最关键的点是“暂停”和“恢复”。用一段代码说明下:void foo() { code1; code2; code3; } int main() { foo(); return 0; }代码5这是一段普通的代码,代码从main函数开始,先调用
foo函数,接着依次调用code1、code2、code3,然后返回main函数,最后执行return 0。这种执行顺序是我们见到的最常见的顺序,代码逐行执行,按部就班符合我们的预期。但是如果是协程,代码就可以在执行完code1后立马返回到main函数,在适当时候再返回foo执行code1后面的代码code2——这就是前面所谓的“暂停”和“恢复”。其实仔细想想所谓协程也只是计算机执行顺序的一种规范,有点类似goto指令,都是用于改变常规的代码执行顺序,只是这些规范我们用的比较少见而已。其实翻阅维基百科的“协程”页面[9],你会发现其实协程历史并不短,起码已经超过半个世纪了。但是直到最近几年才开始火热是有原因的,就像goto语句一样,过多的自由有时也是一种灾难(代码逻辑混乱,难以维护)。但是随着计算机硬件的发展(多核多线程)和一些成熟的案例(如腾讯的libco[10]和golang[11])出现,让人们认识到了协程的优势和闪光点。 -
协程是无栈的。
“无栈” 两个字隐藏了太多的概念,对于一个完全没有接触过协程的人来说这个概念太含糊和陌生了。这里的“无栈”是相对于协程的另一种实现方式“有栈”协程而言的。在介绍这两个概念前先看下普通函数调用堆栈。函数堆栈非正式的理解就是函数调用时申请的用于存放参数和临时变量的内存块,按照后进先出(LIFO, Last In First Out)的规则分配内存,因为只有push和pop两种操作所以比较简单和快捷,由编译器自动管理其分配内存的生命周期。 在https://godbolt.org/里写下测试代码得到如下汇编指令:
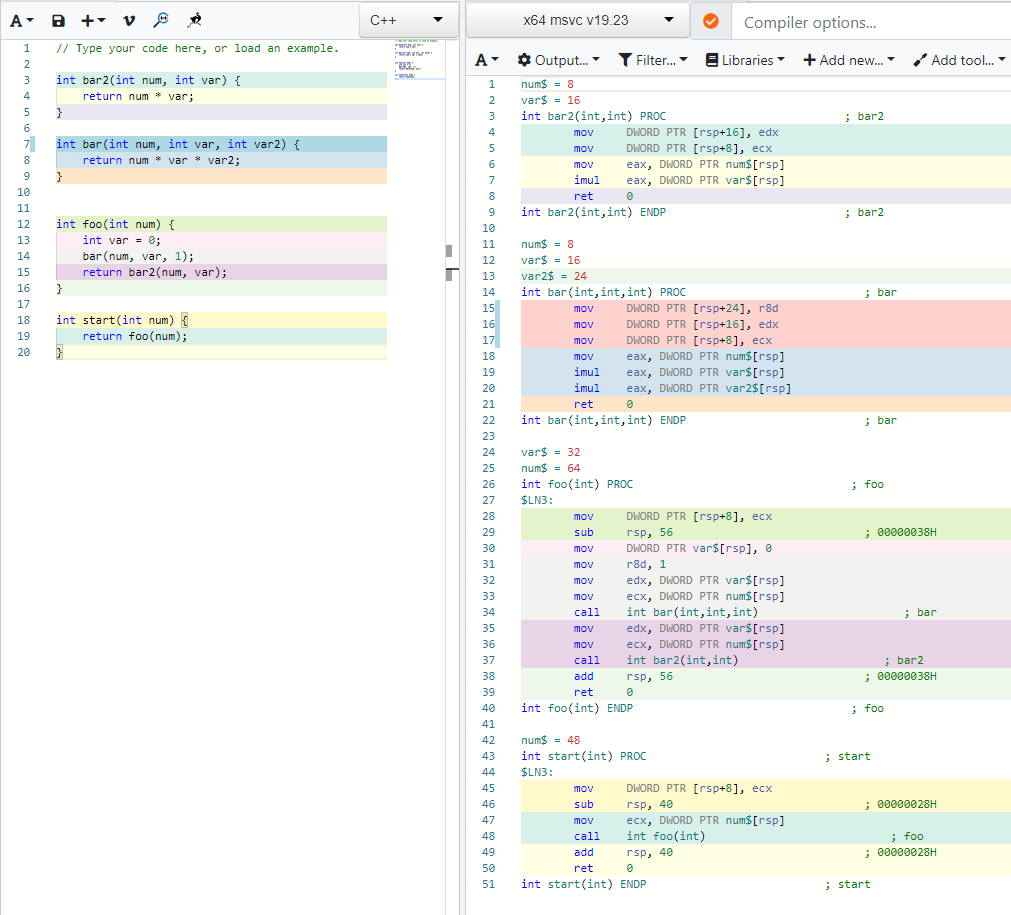
图1 函数调用汇编分析源码经过简单整理可得到堆栈的使用情况如下图所示:

图2 函数调用堆栈变化
注意
上面的代码是使用
x64位的msvc编译的,和经常见到x86版本相比64位版本的更加简洁易懂,少了“基址指针寄存器”的概念所以省去了保存和恢复基址指针的操作。这里也没有常规的push和pop操作,而是直接通过sub和add相应的地址偏移获得相同的效果。
通过上面的分析我们可以看到,每次进行函数调用我们都需要为被调用的函数分配栈空间,用以保存调用参数和局部变量。为了实现协程,我们必须要实现前面说的“暂停”和“恢复”特性。有栈协程为了实现这两个特性做法是想办法在暂停后保存这些参数、变量以及相关的寄存器,在需要恢复调用前再将保存的信息恢复。在
Linux中可以调用ucontext族函数getcontext、setcontext等实现[12];Boost库也有类似的实现Boost.Context[13];甚至可以自己通过汇编实现,例如微信的libco[14]。无栈协程不需要此过程。 在《使用 C 语言实现协程》[15]文章作者详细介绍了一种利用达夫设备[16]原理使用C语言实现协程的方法。由于原理比较简单在此粗略的介绍下其核心代码:
int function(void) { static int i, state = 0; switch (state) { case 0: // 函数开始执行 for (i = 0; i < 10; i++) { state = 1; // 我们会回到 "case 1" 的地方 return i; case 1:; // 从上一次返回之后的地方开始执行 } } return i; }第1次调用
function()时, state值为0,所以执行case 0,然后执行for循环体,i赋0, state赋1(相当于保存状态,暂停执行),函数返回i(0)。 第2次调用function()时, state值为1,执行case 1(相当于恢复状态,继续执行),执行for循环后面的语句,i++, state赋1,函数返回i(1)。 第3次调用function()时, state值为1,执行case 1,执行for循环后面的语句,i++, state赋1,函数返回i(2)。 …第10次调用
function()时, state值为1,执行case 1,执行for循环后面的语句,i++, state赋1,函数返回i(9)。 第11次调用function()时, state值为1,执行case 1,因为i>=10所以跳出循环,函数返回i(9)。由此可见,通过一个状态量,便可改变每次函数的执行流程。看到这里也许你会有疑问,为什么要用这么复杂的语法,if-else不也可以实现吗?其实这样写主要方便利用宏进行代码封装,具体的做法可见参考文献[15]。其实在C++协程标准的实现里面也有类似的做法,只不过是编译器通过汇编指令直接跳转实现的,具体的分析后面会介绍。
-
它们通过返回到调用方暂停执行。这里说的是协程的非对称性,协程按照调度方式可以分为对称协程和非对称协程[17]。
- 对称协程 Symmetric Coroutine:任何一个协程都是相互独立且平等的,调度权可以在任意协程之间转移。
- 非对称协程 Asymmetric Coroutine:协程出让调度权的目标只能是它的调用者,即协程之间存在调用和被调用关系。
直白的说就是, 对称协程只提供了一种类似于goto的操作将控制权直接传递给其它指定的协程,而非对称协程需要前面所说的“暂停”和“恢复”两种操作。对于对称协程调用者和被调用者之间的关系是平等的,他们甚至可以互相调用,可以做到A->B->C->A(A,B,C为不同的协程函数)这样的链式调用。非对称协程具有明确的层级关系被调用者必须先返回到调用者再调用其他协程,如A->B->A->C->A。粗看好像对称协程更容易使用,因为其具有更大的自由度,但是它和goto遇到的问题是一样的,在一个复杂的系统里过多的自由跳转会破坏代码的结构,让程序逻辑不容易得到把控。例外对称协程只是非对称协程的一个特例,我们可以通过添加一个中立的第三方调度中心的方式将非对称协程转换成对称协程(只需要在所有协程“暂停”时将控制权转交给调度中心统一调度即可)。
-
并且从栈分离存储恢复所要求的数据。这里所说是相对于普通的函数调用,如图1,图2所示,我们在调用函数时总是会先将调用参数和临时变量以及一些相关寄存器信息压入堆栈,在后面的指令需要时再从堆栈中取出,最后函数执行完后清理掉。但是协程具有额外的“暂停”和“恢复”操作,如果还是使用堆栈上的信息,根据堆栈的使用规则,协程“恢复”后堆栈已经遭到破坏,因为“暂停”后为了使调用者能够正常工作,我们必须保证此时的堆栈状态能够恢复到调用者的堆栈状态,“恢复”后由于协程的堆栈信息已经丢失,我们无法再使用协程的堆栈。所以我们需要额外的手段将这些信息存储在其他地方(一般是在堆上)。值得注意的是这里的用词是“分离”而不是复制,具体实现后面做详细的分析。
-
这允许编写异步执行的顺序代码(例如不使用显式的回调来处理非阻塞 I/O)。 参考前面代码4的例子。
-
还支持对惰性计算的无限序列上的算法及其他用途。
-
无限序列(infinite sequence)是指一列或一串离散的数字能够与另一组正整数$$\{0, 1, 2, 3, …\}$$相比而形成一定的联系和概念。例如无限序列 $$ N=(0, 1, 2, 3, …) $$ 和 $$ S=(1, \frac{1}{2}, \frac{1}{4}, \frac{1}{8}, …, \frac{1}{2^n}, …) $$, 当然斐波纳契数列$$ F=(1, 1, 2, 3, 5, 8, …, n_{i-1}, n_{i}, n_{i-1} + n_{i}, …) $$也是一种无限序列。
-
惰性计算(又称延迟求值)在科学计算和函数式编程中经常用到的一种优化手段。引用
Wiki中给的例子简单说明下, 下面是部分代码[19]:matrix A,B; A[3][4]=101; B[3][4]=102; matrix_add R=A+B; int result = R[3][4];上面的代码是计算两个矩阵(A, B)相加后得到新矩阵(R)某个索引的值。通常我们在执行完
R=A+B时便会算出R中的所有元素,因为A和B均有$12=3\times4$个元素,所以为了得到R需要经过12次加法运算,但是我们只需要R[3][4]这一个元素的值,所以我们浪费了11次运算。惰性计算的方法是执行到R=A+B时,我们并不去计算,而只是存储计算所需要的数据,计算被延迟到了取R[3][4]值时才开始。完整的代码请参考Wiki[19]。 -
我们通过
cppcoro计算斐波纳契的例子来说明下C++协程是怎么实现惰性计算的。cppcoro::generator<const std::uint64_t> fibonacci() { std::uint64_t a = 0, b = 1; while (true) { co_yield b; // 2 auto tmp = a; a = b; b += tmp; } } void usage() { for (auto i : fibonacci()) // 1 { if (i > 1'000'000) break; std::cout << i << std::endl; } }在代码注释1处,我们通过循环不停调用fibonacci, 第一次调用fibonacci时从函数入口开始初始化a, b,然后进入循环,执行
co_yield b;这是会从fibonacci函数回到usage,执行for循环体中代码,再次调用fibonacci时实际上执行的是fibonacci协程的的resume方法,所以再次进入fibonacci函数时并不是从入口重新执行,而是恢复到co_yield后面的语句auto tmp = a;继续执行算出数列的下个值b,然后循环再次co_yield回到usage,如此循环往复,最终得到数列中第1'000'000个值。 可以看到第一次调用时我们并没有把fibonacci数列中的前1'000'000个值全部计算出来,而是把计算推迟到了后面的调用。如果有足够的时间和算力我们可以计算任意数列的值,从算法上并不限制数列的长度,可以无限的计算下去, 所以说是“无限序列”。
-
-
若函数的定义做下列任何内容之一,则它是协程。 简单的说就是如果一个函数中出现co_await、co_yield、co_return 三个关键字,你就可以认为它是一个协程函数。
原理剖析
C++语言的难学已经是恶名远播,提起C++时许多程序员(甚至是学C语言的程序员)第一反应就是“这是个令人胆颤、难缠、恶心的家伙”。其实换个角度C与C++的关系非常类似于JavaScript和Typescript(如果你用过应该很好理解),C++作为C的超集经过编译器的转换绝大部分的代码是可以转换成C,因为有了编译器的帮助C++可以实现许多高级的封装,每次编译时编译器都会根据需要向用户编写的代码里“偷偷”加料。例如构造析构函数的自动创建、虚函数表、this指针传递等等,对于这方面的知识建议大家看看《深入了解c++内核对象模型》这本书。因为编译器的这些小动作对用户是无感知的,这就造成了用户对C++一些行为表现的困惑,也加大了大家学习C++的难度。而协程特性是我目前见到C++让编译器加料最多的一次,理所当然理解的难度指数也是陡增。现在就让我们细细的分析下编译器给我们加的这些料的配方吧!
协程函数展开
让我们看个最简单的例子,看看main函数调用remote_query_all时发生了什么。
我们先定义个函数返回对象的类型return_ignore,为什么要定义它以及怎么定义我们后面介绍,提前申明只是不想干扰后面的分析,如果不清楚具体的含义就先无视它。
struct return_ignore {
struct promise_type {
return_ignore get_return_object() {
return return_ignore{};
}
auto initial_suspend() {
return std::experimental::suspend_always{};
}
auto final_suspend() {
return std::experimental::suspend_never{};
}
void unhandled_exception() {
}
void return_void() {}
};
};
下面是我们现在需要关注的代码,为了排除干扰我已经做了最大程度的精简。test_coroutine的模板参数其实是不必要的,但是为了通用性还是加上了。
#include <experimental/coroutine>
template<typename ...Args>
return_ignore test_coroutine(Args... args) {
co_await std::experimental::suspend_always{};
}
int main() {
test_coroutine();
return 0;
}
下面我们看看编译器展开test_coroutine函数后的代码成什么样子, Gor Nishanov和luncliff对其做了精彩的分析,推荐看看他们的报告[21][22],下面是我结合他们俩的报告整理出来的全部展开:
template<typename ...Args>
return_ignore test_coroutine(Args... args) {
using T = coroutine_traits<return_type, Args...>;
using promise_type = T::promise_type;
using frame_type = tuple<frame_prefix, promise_type, Args...>;
auto *frame = (frame_type *)promise_type::operator new(sizeof(frame_type));
auto *p = addressof(get<1>(*frame));
return_ignore*__return_object;
*__return_object = { p->get_return_object() };
{
// co_await p->initial_suspend();
auto&& tmp = p->initial_suspend();
if (!tmp.await_ready()) {
__builtin_coro_save() // frame->suspend_index = n;
if (tmp.await_suspend(<coroutine_handle>)) {
__builtin_coro_suspend() // jmp
}
}
resume_label_n:
tmp.await_resume();
}
try {
// co_await std::experimental::suspend_always{};
{
auto&& tmp = std::experimental::suspend_always{};
if (!tmp.await_ready()) {
__builtin_coro_save() // frame->suspend_index = m;
if (tmp.await_suspend(<coroutine_handle>)) {
__builtin_coro_suspend() // jmp
}
}
resume_label_m:
p->return_void(tmp.await_resume());
// p->return_value(tmp.await_resume());
}
goto __final_suspend_point;
} catch (...) {
p->unhandled_exception();
}
__final_suspend_point:
co_await p->final_suspend();
__destroy_point:
promise_type::operator delete(frame, sizeof(frame_type));
}
哈哈,惊不惊喜?意不意外?你的一行代码,编译器给你加了这么多东西。上面的代码对理解协程非常重要,它就像导航地图里面的预览图一样,在你学习协程的各种知识和概念是不被绕晕。我在刚开始学习协程时就因为缺乏对全局的理解,导致当面对一大堆新的概念时不说其它的,心理上就有莫大压力,想理清它们关系也无所适从,希望上面的代码能够帮助到你。
注意
上面的代码并非真实的代码,只是根据文献和逆向推导而来,而且各个编译器厂商实现也有差异,这里列出的代码只是帮助大家理解而已。
下面我们对照着上面的代码说说协程的几个重要概念。
co_await 表达式
co_await 表达式, 就是我们在co_await关键词后面的运算对象(operand),这个运算对象必须满足特定的规则:必须包含await_ready、await_suspend、await_resume三个函数。通过展开的代码我们很容易理解为什么做这样的规定。例如我们前面例子中std::experimental::suspend_always的定义是这样的:
struct suspend_always {
bool await_ready() noexcept {
return false;
}
void await_suspend(coroutine_handle<>) noexcept {}
void await_resume() noexcept {}
};
co_await 表达式展开后是这样的:
// co_await std::experimental::suspend_always{};
{
auto&& tmp = std::experimental::suspend_always{};
if (!tmp.await_ready()) {
__builtin_coro_save() // frame->suspend_index = m;
if (tmp.await_suspend(<coroutine_handle>)) {
__builtin_coro_suspend() // jmp
}
}
resume_label_m:
tmp.await_resume();
}
可以看到展开后直接调用了运算对象的await_ready、await_suspend、await_resume三个方法。那么这三个函数式作什么用的呢?
await_ready: 在暂停协程前给了一次机会,判断是否可以避免异步调用以达到节省暂停带来的开销。await_suspend:可以看做是暂停前的准备,通常我们在这个函数中分配任务系统,线程去完成异步完成,然后进入暂停状态。注意这个函数有一个非常重要的参数coroutine_handle(协程句柄),通过这个句柄我们可以操控协程的状态,通常我们需要将这个句柄保存起来,在适当的时机(异步任务完成时)通过它恢复当前协程。await_resume:这个很好理解,协程恢复后执行的代码,值得注意的是恢复后而不是回复前。
承诺(promise)对象
编译器用 std::coroutine_traits 从协程的返回类型确定 Promise 类型[8]。也就是说编译器会根据你的协程函数放回值类型去确定Promise类型,确定方法就是看你的返回类型有没有promise_type的定义,比如return_ignore的Promise类型就是return_ignore::promise_type。这个Promise类型类似于std::promise,应为是异步所以无法立即给你结果,但是我承诺你将来你可以向我申请查询结果。同样通过展开代码我们可以看到编译器调用了Promise的许多方法,所以我们在定义promise_type时必须符合编译的规范和需求。下面是promise_type必须具有的接口:
-
get_return_object: 按照规定该调用的结果将在协程首次暂停时返回给调用方[8]。调用者可以通过此函数返回的对象获得协程函数最终的结果。可以参考return_ignore的代码,这里需要注意的是我们不能将结果保存在promise_type里,因为协程函数结束时会析构这个对象,保存的数据会丢失。可选的方案是在promise_type中保存返回对象然后在返回去,如下面的代码,但是返回值类型是个问题,如果返回_ret指针,promise_type析构后_ret一样会被收回,返回对象会多出一份数据,return_value函数操作的还不是同一个对象, 所以_value只能是个指针类型。还有个小的问题是直接在内部类声明外面的类对象会导致类型未定义的错误,只能放到类定义外面定义内部类。struct return_object { struct promise_type; int get_ret() { return *_value; } private: std::shared_ptr<int> _value = std::make_shared<int>(0); }; struct return_object::promise_type { return_object get_return_object() { return _ret; } ... void return_value(int value) { *_ret._value = value; } return_object _ret; };另一个方案是在promise_type类中提供个方法让返回对象将this指针传给promise_type类,相当于来了个回马枪:
struct return_object { struct promise_type { return_object get_return_object() { return return_object(this); } void set_return_object(return_object* ret) { _ret = ret; } auto initial_suspend() { return std::experimental::suspend_never{}; } auto final_suspend() { return std::experimental::suspend_never{}; } void unhandled_exception() { } void return_value(int value) { _ret->_value = value; } return_object* _ret = nullptr; }; int get_ret() { return _value; } private: return_object(promise_type* p) { p->set_return_object(this); } int _value = 0; }; -
initial_suspend: 控制是否在进入协程函数前先暂停协程。 -
initial_suspend: 做些收尾工作。 -
unhandled_exception: 参考展开代码,捕获到异常时调用此方法。 -
return_value,return_void: 这两个函数根据协程函数内的co_return表达式二选一即可,协程函数遇到co_return会根据表达式内容调用这两个函数之一,并将结果传递给放回对象。
协程句柄 (coroutine handle)
这是用于恢复协程执行或销毁协程帧的非拥有柄。前面的“承诺对象”是从内部控制协程,将异常和结果传递给系统外部,而协程句柄正好相反,它提供了从外部操控协程的方法。先看下结构声明:
template <>
struct coroutine_handle<void> { // no promise access
static coroutine_handle from_address(void* _Addr);
void* address() const noexcept;
void operator()() const noexcept {
resume();
}
void resume() const {
_coro_resume(_Ptr);
}
void destroy() {
_coro_destroy(_Ptr);
}
bool done() const {
return _Ptr->_Index == 0;
}
struct _Resumable_frame_prefix {
using _Resume_fn = void(__cdecl*)(void*);
_Resume_fn _Fn;
uint16_t _Index;
uint16_t _Flags;
};
protected:
_Resumable_frame_prefix* _Ptr = nullptr;
};
在协程句柄中我们看到一个非常重要的方法resume和一个frame_prefix的成员变量,resume方法应该不用多说了,调用它可以将协程从“暂停”的地方“恢复”。有意思的是_Ptr这个指针,它的类型是_Resumable_frame_prefix, 其中包括一个函数指针_Fn和两个状态值。_Fn其实就是协程跳转后真正执行的函数地址,它通过和_Index配合能够跳转到协程暂停后的指令地址。具体的分析参考后面的协程跳转相关内容。
协程状态 (coroutine state)
可以把协程状态理解为为使协程正常工作在堆上申请分配的内存,这里面包括前面说过的承诺对象、参数、临时变量和协程句柄里面记录的_Resumable_frame_prefix内容。
协程跳转
在协程展开代码中还有两个函数__builtin_coro_save和__builtin_coro_suspend,这其实是编译器内置的代码,在msvc的头文件experimental\resumable中你可以看到许多以_coro_开头的类似函数,这些函数式协程实现的基础。下面我们以一个简单的例子,通过跟踪汇编代码来看下编译器是怎么实现协程的“暂停”和“恢复”操作的。
std::experimental::coroutine_handle<> g_h;
struct awaitee {
bool await_ready() noexcept {
return false;
}
void await_suspend(std::experimental::coroutine_handle<> h) noexcept {
g_h = h;
}
void await_resume() noexcept {}
};
template<typename ...Args>
return_object test_coroutine(Args... args) {
co_await awaitee();
co_return 1;
}
int main() {
auto& ret = test_coroutine();
if (ret.get_ret() == 0) {
g_h.resume();
}
std::cout << "coroutine ended." << ret.get_ret() << std::endl;
return 0;
}
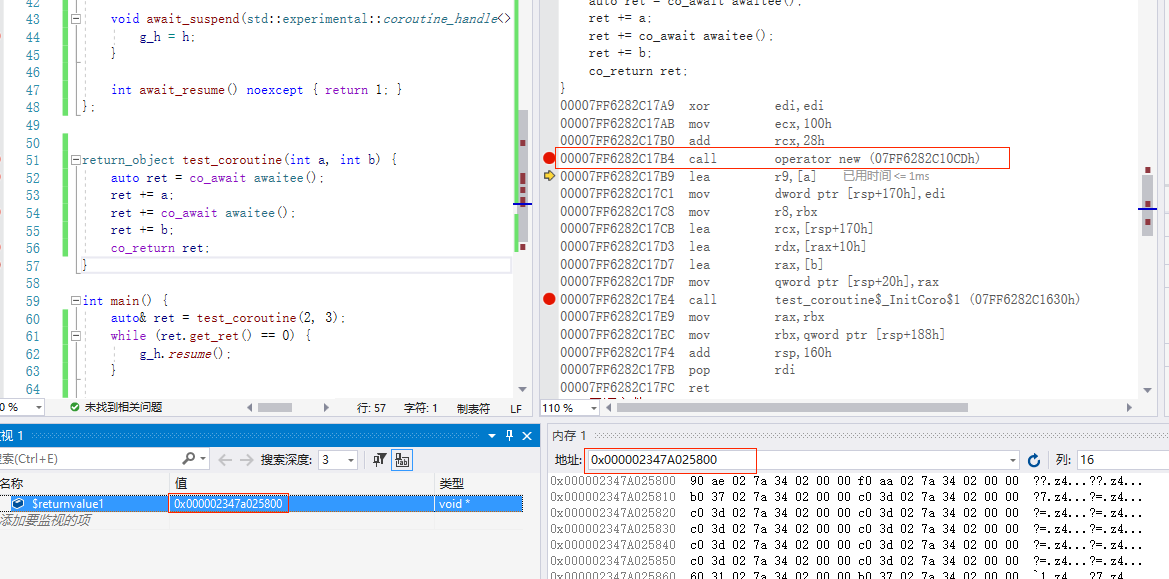
; test_coroutine
xor edi,edi
mov ecx,100h
add rcx,28h
call operator new (07FF6282C10CDh) ; 在堆上分配协程帧内存
lea r9,[a] ;向_InitCoro 传递 test_coroutine 参数 a
mov dword ptr [rsp+170h],edi
mov r8,rbx
lea rcx,[rsp+170h]
lea rdx,[rax+10h] ; 计算协程句柄地址
lea rax,[b] ;向_InitCoro 传递 test_coroutine 参数 b
mov qword ptr [rsp+20h],rax
call test_coroutine$_InitCoro$1 (07FF6282C1630h) ; 调用初始化协程的内置函数
请在后面注意这里的内存变化:
这里值得一提的是计算协程句柄地址中的偏移地址10h, 这个值怎么来的呢? 翻看msvc中resumable头文件,可以看到coroutine_handle的定义:
template <typename _PromiseT>
struct coroutine_handle : coroutine_handle<> {
static coroutine_handle from_promise(_PromiseT& _Prom) noexcept {
auto _FramePtr = reinterpret_cast<char*>(_STD addressof(_Prom)) + _ALIGNED_SIZE;
coroutine_handle<_PromiseT> _Result;
_Result._Ptr = reinterpret_cast<_Resumable_frame_prefix*>(_FramePtr);
return _Result;
}
...
static const size_t _ALIGN_REQ = sizeof(void*) * 2;
static const size_t _ALIGNED_SIZE =
is_empty_v<_PromiseT> ? 0 : ((sizeof(_PromiseT) + _ALIGN_REQ - 1) & ~(_ALIGN_REQ - 1));
_PromiseT& promise() const noexcept {
return *const_cast<_PromiseT*>(
reinterpret_cast<_PromiseT const*>(reinterpret_cast<char const*>(_Ptr) - _ALIGNED_SIZE));
}
};
从中分析可以知道promise地址(实际上就是协程栈的地址)与协程句柄的帧前缀地址是可以互相转换的,这两个地址之间相差了_ALIGNED_SIZE字节,所以得到一个地址相加或相减便能转换成另一个地址。那么_ALIGNED_SIZE是怎么算出来的呢?其实这是根据我们定义的promise_type的大小进行字节对齐(两倍的sizeof(void*))得到的。例如我们定义的return_object::promise_type里面有一个指针成员变量,所以它的大小为8(64位机器)在和sizeof(void*) * 2 == 16 == 10h对齐后得到的结果便是16即10h, 如果我们在promise_type里面定义三个指针变量,大小变为24与16字节对齐后变为32即20h。
下面我们继续分析_InitCoro函数:
mov qword ptr [rsp+10h],rdx ; 从前面的分析我们知道rdx其实是协程句柄帧前缀的地址
sub rsp,28h
mov r11d,100h
mov rax,qword ptr [&b] ; 参数b
mov r10d,dword ptr [rax]
mov eax,dword ptr [r9] ; 参数a
mov dword ptr [rdx+r11+10h],eax ; 加参数a, 存入协程栈
mov dword ptr [rdx+r11+14h],r10d ; 将参数b, 存入协程栈
lea rax,[test_coroutine$_ResumeCoro$2 (07FF6282C2FF0h)] ; 协程函数入口地址
mov qword ptr [rdx],rax ; 初始化协程句柄帧前缀的_Fn变量
mov eax,10002h ; 初始化协程句柄帧前缀的_Index和_Flags变量, 注意这里的_Index初始化值为2
mov r9d,2
cmp dword ptr [rcx],0
cmovne eax,r9d
mov dword ptr [rdx+8],eax
xor eax,eax
mov dword ptr [r8],eax
mov qword ptr [rdx-10h],r8 ; 初始化我们定义的 promise_type 的 _ret 变量
; 注意这里的地址是 rdx-10h,即协程帧地址
mov byte ptr [rdx+r11],al
mov rcx,rdx
call test_coroutine$_ResumeCoro$2 (07FF6282C2FF0h)
nop
add rsp,28h
ret
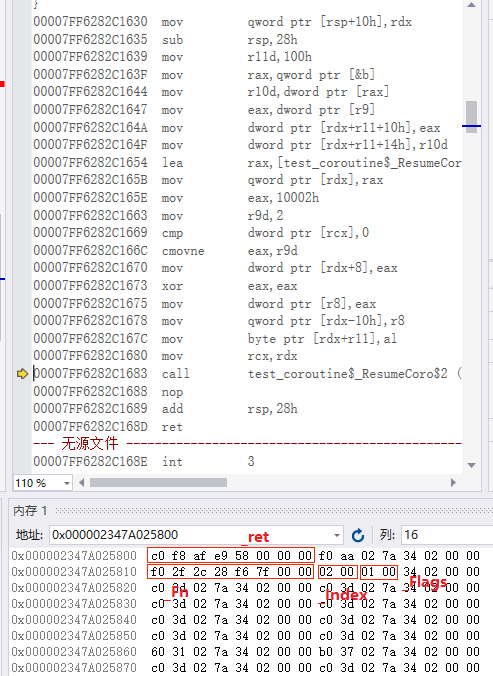
接着看下_ResumeCoro:
mov qword ptr [rsp+8],rcx
sub rsp,38h
mov r8,qword ptr [<coro_frame_ptr>] ; 帧地址
movzx eax,word ptr [r8+8] ; 获得_Index值
mov word ptr [rsp+20h],ax
inc ax ; _Index + 1,获得`恢复`索引, _Index为`暂停`索引
cmp ax,8
ja test_coroutine$_ResumeCoro$2+12Dh (07FF6282C311Dh)
movsx rax,ax
lea rdx,[__ImageBase (07FF6282C0000h)] ; 获取索引表
mov ecx,dword ptr [rdx+rax*4+3124h] ; 计算下条指令的执行地址偏移
add rcx,rdx ; 计算下条指令的执行地址
jmp rcx ; 跳转
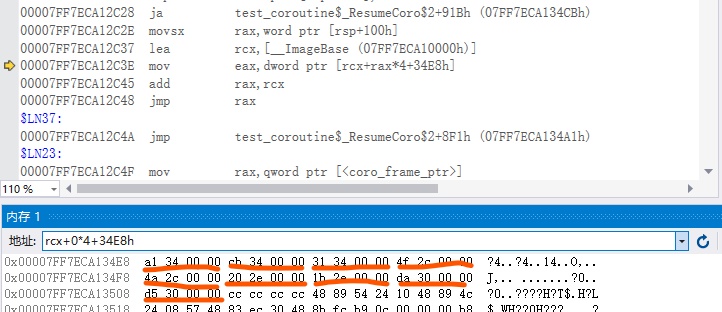
这段代码可以说是协程实现的最关键的地方了,通过指令mov ecx,dword ptr [rdx+rax*4+3124h] 我们甚至可以猜测到隐藏在编译器后面整个实现逻辑。因为编译器在编译时知道我们所有代码的执行地址,所以编译器在生成程序时帮我建立了一张表
| 恢复点地址 |
|---|
| 恢复点1 |
| 恢复点2 |
| … |
编译器每次遇到co_await, co_yied, 或者其他需要暂停恢复的地方都往这个表里添加一条记录。在执行时每次暂停,恢复时修改_Index值来动态找到需要跳转的地址。解释下为什么_Index初始化时值为2, 因为第一个暂停点和恢复点时留给cancel操作的。怎么样这里的逻辑是不是有点“达夫设备”的感觉,只是编译器做的更好。下面我们来验证下各个跳转点:

从上面的代码可以看出,rcx是一个内存映射好的地址,现在让我们分别加上前面的地址偏移看看jmp最终跳转到的代码时什么。
-
第1个 rax = rcx + (rcx+0*4+34E8h) = 0x00007ff7eca10000 + 0x000034a1 (注意这里的字节序,需要反过来取值) = 0x00007ff7eca134a1,
-
第2个 rax = rcx + (rcx+1*4+34E8h) = 0x00007ff7eca10000 + 0x000034cb = 0x00007ff7eca134cb 看下0x00007ff7eca134a1和0x00007ff7eca134cb地址处的代码:
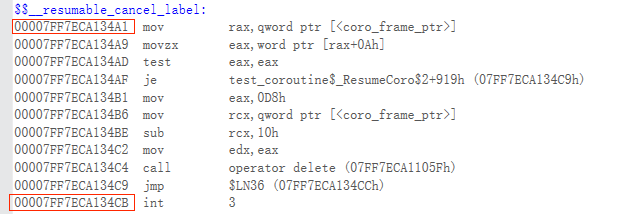
可以很容易的发现这是_resumable_cancel函数的进入和退出点, 同样我们再看看根据后面几个值算出的地址是什么代码。
-
第3个00007FF7ECA13431是 promise_type展开中的 co_await initial_suspend() 代码
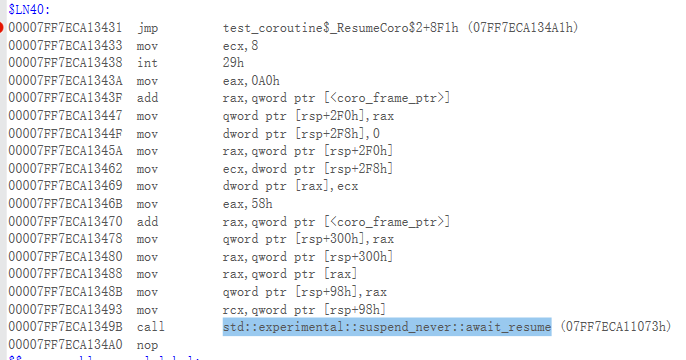
这是 co_await initial_suspend() 的代码
-
第4个0x00007ff7eca12c4f是 第一次进入协程函数的代码。
-
第5个0x00007ff7eca12c4a是 0x00007ff7eca12c4f 失败时的恢复点。
-
第6个0x00007ff7eca12e20是 第一次调用 co_await awaitee() 恢复后代码。
-
第7个0x00007ff7eca12e1b是 0x00007ff7eca12e20 失败时的恢复点。
-
第8个0x00007ff7eca130da是 第二次调用 co_await awaitee() 恢复后代码。
-
第9个0x00007ff7eca130d5是 0x00007ff7eca130da 失败时的恢复点。

从上图可以看到每次失败时都会跳转到 0x00007ff7eca134a1 即 _resumable_cancel函数的进入点。
总结
协程最关键的操作是暂停和恢复函数的执行,C++20中的协程借助于编译器在编译期插入相关代码、记录相应跳转点然后运行期根据协程状态计算跳转地址实现协程的各种功能。希望经过本文的讲解和分析后能够帮助大家更为深刻的了解和理解协程的机理,能够让大家放下对协程的恐惧,在以后的使用中能够更加自信。
比如很多人在使用协程时都会想协程时线程安全的吗?其实在我看来这是个伪命题,既然是问是否是线程安全,那么肯定要出现资源被多个线程竞争的情况。但是从我们前面的例子可以看出整个代码都是在一个线程执行的,所以谈不上线程安不安全。当然如果我们改下前面的代码,将resume的调用放在不同线程里面执行,这种情况下协程函数中如果使用了共享的对象,那肯定不是线程安全的。至于网上许多说协程没有线程安全问题应该是指在一个协程函数中多次暂停和恢复,由于是顺序进行的,所以协程对象上的变量在此过程中不会存在竞争,可以说是线程安全的。总之,线程是否安全关键还是看线程而不是协程,协程只是改变代码执行流程的一种手段。
在使用协程时,我们关心的另一问题就是性能效率问题。在理解C++的协程原理后我们知道建立一个协程函数后需要建立个协程对象,这个协程对象中包含承诺对象、形参信息、临时变量、协程句柄。与回调函数比起来真正多出来的应该只有协程句柄内包含的信息,承诺对象相当于返回值, 形参和临时变量回调函数也是少不了的(协程经过编译器优化可以直接在堆上分配),而协程句柄的内存也是极少的(只有一个函数指针和两个状态值)。对于执行时间,协程跳转只需计算一个地址然后直接跳转,效率上不会比一次函数调用差多少。所以C++的协程无论是空间还是时间复杂度性能都是相当可观的。
最后,回到开头我是因为看到asio中的协程示例才开始学习研究C++ Coroutine的,但是此文通篇都没有提及asio, 所以在下篇文章中我会带大家一起学习研究下asio是怎样使用协程实现异步调用的。
参考引用
[1] C++ compiler support[EB/OL]. https://en.cppreference.com/w/cpp/compiler_support
[2] “Hello, World!” program[EB/OL].https://en.wikipedia.org/wiki/%22Hello,_World!%22_program
[3] C++ Standards Support in GCC[EB/OL].https://gcc.gnu.org/projects/cxx-status.html#cxx98
[4] std::this_thread::get_id[EB/OL].https://en.cppreference.com/w/cpp/thread/get_id
[5] User-defined literals[EB/OL].https://en.cppreference.com/w/cpp/language/user_literal%23Standard_library
[6] reactor反应堆模式[EB/OL].https://aceld.gitbooks.io/libevent/content/31_reactorfan_ying_dui_mo_shi.html
[7] Proactor and Boost.Asio[EB/OL].https://www.boost.org/doc/libs/1_47_0/doc/html/boost_asio/overview/core/async.html
[8] Coroutines (C++20)
[EB/OL].https://en.cppreference.com/w/cpp/language/coroutines
[9] 协程
[EB/OL].https://zh.wikipedia.org/zh-cn/%E5%8D%8F%E7%A8%8B
[10] Tencent/libco[EB/OL].https://github.com/Tencent/libco
[11] Go Language Patterns/Coroutines[EB/OL].http://www.golangpatterns.info/concurrency/coroutines
[12] setcontext(2) - Linux man page[EB/OL].https://linux.die.net/man/2/setcontext
[13] Boost.Context[EB/OL].https://www.boost.org/doc/libs/1_74_0/libs/context/doc/html/context/overview.html
[14] Libco[EB/OL].https://github.com/Tencent/libco
[15] 使用 C 语言实现协程[EB/OL].https://mthli.xyz/coroutines-in-c/
[16] 达夫设备[EB/OL].https://en.wikipedia.org/wiki/Duff%27s_device
[17] 破解 Kotlin 协程 番外篇(2) - 协程的几类常见的实现[EB/OL].https://www.bennyhuo.com/2019/12/01/coroutine-implementations/
[18] infinite sequence:无限序列[EB/OL].https://searchcio.techtarget.com.cn/whatis/8-28809/
[19] 惰性求值[EB/OL].https://zh.wikipedia.org/wiki/%E6%83%B0%E6%80%A7%E6%B1%82%E5%80%BC
[20] CppCoro - A coroutine library for C++[EB/OL].https://github.com/lewissbaker/cppcoro
[21] Exploring the C++ Coroutine[EB/OL].https://raw.githubusercontent.com/CppCon/CppCon2016/master/Presentations/C%2B%2B%20Coroutines%20-%20Under%20The%20Covers/C%2B%2B%20Coroutines%20-%20Under%20The%20Covers%20-%20Gor%20Nishanov%20-%20CppCon%202016.pdf
[22] Exploring the C++ Coroutine[EB/OL].https://luncliff.github.io/coroutine/ppt/%5BEng%5DExploringTheCppCoroutine.pdf