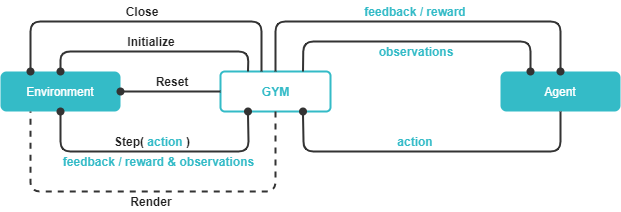
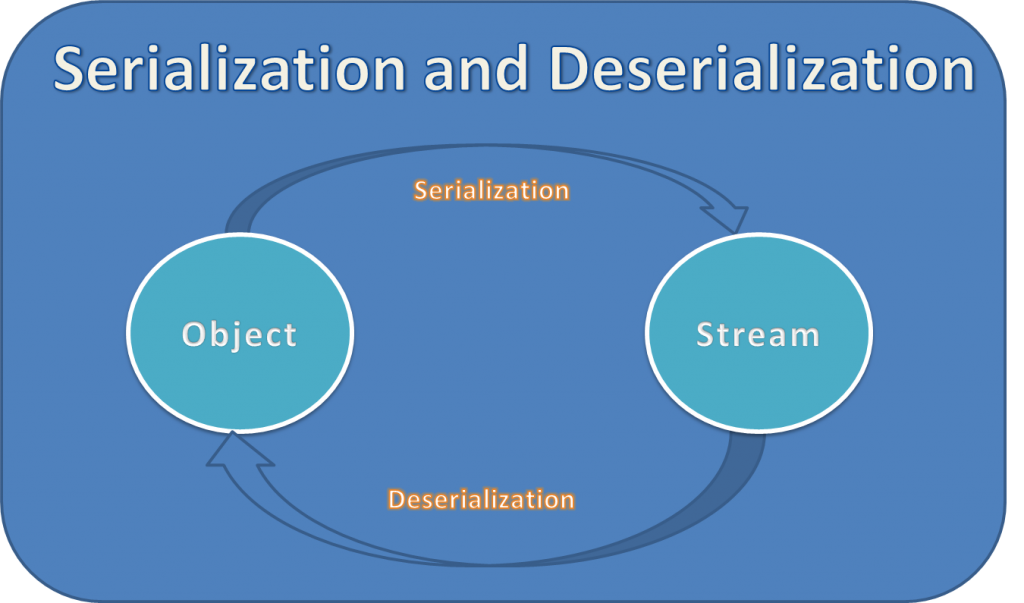
test
\documentclass[UTF8]{ctexart} \usepackage{markdown} \begin{document} \begin{markdown}
我是 Markdown 这里可以用 Markdown 语法,撰写各种内容。例如,我可以强调,也可以加粗,当然也可以加粗并强调。
这里是二级标题 幸福的获得,在极大的程度上却是由于消除了对自我的过分关注。 —Bertrand Arthur William Russell
你看,我还可以使用引用↑。
关于 dash, en-dash 和 em-dash LaTeX 使用者都应该知道 dash, en-dash 和 em-dash。dash 是普通的连字符,举例如:「five-year-old boy」。en-dash 是表示范围的稍长的横线,举例如:「以下章节是重点:12–15」。em-dash 则是英文中的破折号,举例如:「—Bertrand Arthur William Russell」 \end{markdown} \end{document}
math <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/katex@0.11.1/dist/katex.min.css" integrity="sha384-zB1R0rpPzHqg7Kpt0Aljp8JPLqbXI3bhnPWROx27a9N0Ll6ZP/+DiW/UqRcLbRjq" crossorigin="anonymous">
<script defer src="https://cdn.jsdelivr.net/npm/katex@0.11.1/dist/katex.min.js" integrity="sha384-y23I5Q6l+B6vatafAwxRu/0oK/79VlbSz7Q9aiSZUvyWYIYsd+qj+o24G5ZU2zJz" crossorigin="anonymous"></script>
<script defer src="https://cdn.jsdelivr.net/npm/katex@0.11.1/dist/contrib/auto-render.min.js" integrity="sha384-kWPLUVMOks5AQFrykwIup5lo0m3iMkkHrD0uJ4H5cjeGihAutqP0yW0J6dpFiVkI" crossorigin="anonymous"
onload="renderMathInElement(document.body, {
// customised options
delimiters: [
{left: '$$', right: '$$', display: true}, // 独立一行显示
{left: '$', right: '$', display: false} // 行内显示
]
});">
</script>
数学数列 $ E=mc^2 $: $$ F=(1, 1, 2, 3, 5, 8, .